
Stop Chasing Algorithms: Do This Instead
Why governance and validation are your actual speed multipliers.

HT4LL-20251202
Hey there,
If you are trying to keep up with every new AI algorithm dropped on arXiv, you have already lost the race.
The speed of innovation in digital health is becoming suffocating for R&D leaders. One week the industry is buzzing about Large Language Models (LLMs) for patient engagement, and the next, the focus shifts to Digital Twins for n-of-1 trials. For executives like you, the pressure to adopt “the next big thing” creates a dangerous conflict with the reality of regulatory compliance and the need for rigorous evidence. You don’t need more tools; you need a structured way to validate the ones that actually move the needle.
Here is the reality check we need to navigate this noise:
Governance is an accelerator, not a bottleneck: Rigorous validation (VVUQ) is the only path to regulatory trust.
Control is better than convenience: Relying on closed-source models (like standard GPT) creates reproducibility risks you can’t afford.
External standards are failing: You cannot rely on journals to vet AI integrity; you must enforce internal standards immediately.
Let’s cut through the hype and look at the evidence.
If you’re feeling paralyzed by the sheer volume of AI options and want to move from “experimental” to “scalable,” then here are the resources you need to dig into to build a resilient strategy:
Weekly Resource List:
AI and Innovation in Clinical Trials (Read time: 15 mins)
Summary: This paper argues that the industry must shift focus from simply adopting powerful algorithms to mandating transparency and rigorous validation. It highlights how AI can optimize eligibility criteria using Real-World Data (RWD) and the use of Digital Twins for synthetic control arms.
Key Takeaway: Stop viewing validation as a compliance burden. Implementing Verification, Validation, and Uncertainty Quantification (VVUQ) is the only way to make your AI models distinct and trusted by regulators.

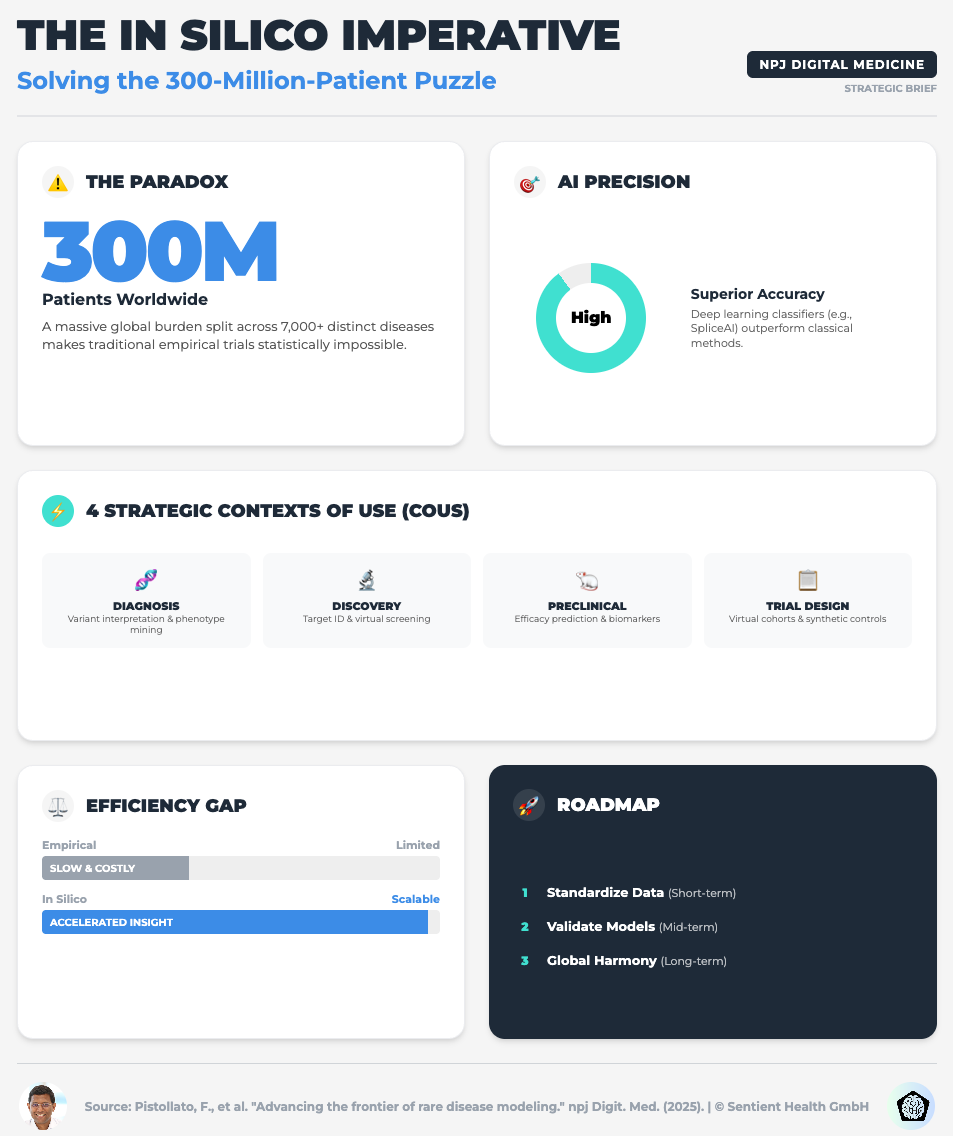
Advancing the Frontier of Rare Disease Modeling (Read time: 25 mins)
Summary: A deep dive into in-silico technologies, exploring how mechanistic models and machine learning are critical for small patient populations. It emphasizes the need for FAIR (Findable, Accessible, Interoperable, Reusable) data standards to make these models work.
Key Takeaway: For rare diseases, you cannot wait for more data. You must use Digital Twins and PBPK models to extrapolate dosing and simulate control arms, but this only works if your data infrastructure is interoperable.
AI in Diabetes Care: From Predictive Analytics to GenAI (Read time: 18 mins)
Summary: This piece explores the implementation challenges of GenAI in chronic disease management. It highlights the potential of GenAI to create privacy-preserving synthetic datasets and the risks of “data colonialism” (bias).
Key Takeaway: To avoid the risks of data privacy and bias, start using Federated Learning. This allows you to train models across diverse institutions without centralized data sharing, ensuring your AI is equitable and robust.

Evaluating AI Guidelines in Family Medicine Journals (Read time: 20 mins)
Summary: A shocking cross-sectional study revealing that only 5% of leading journals endorse AI-specific reporting guidelines like CONSORT-AI. The publishing landscape is failing to standardize AI governance.
Key Takeaway: Do not wait for publishers to set the bar. Mandate CONSORT-AI and SPIRIT-AI guidelines internally for all your R&D teams to safeguard your research credibility before it ever leaves the building.
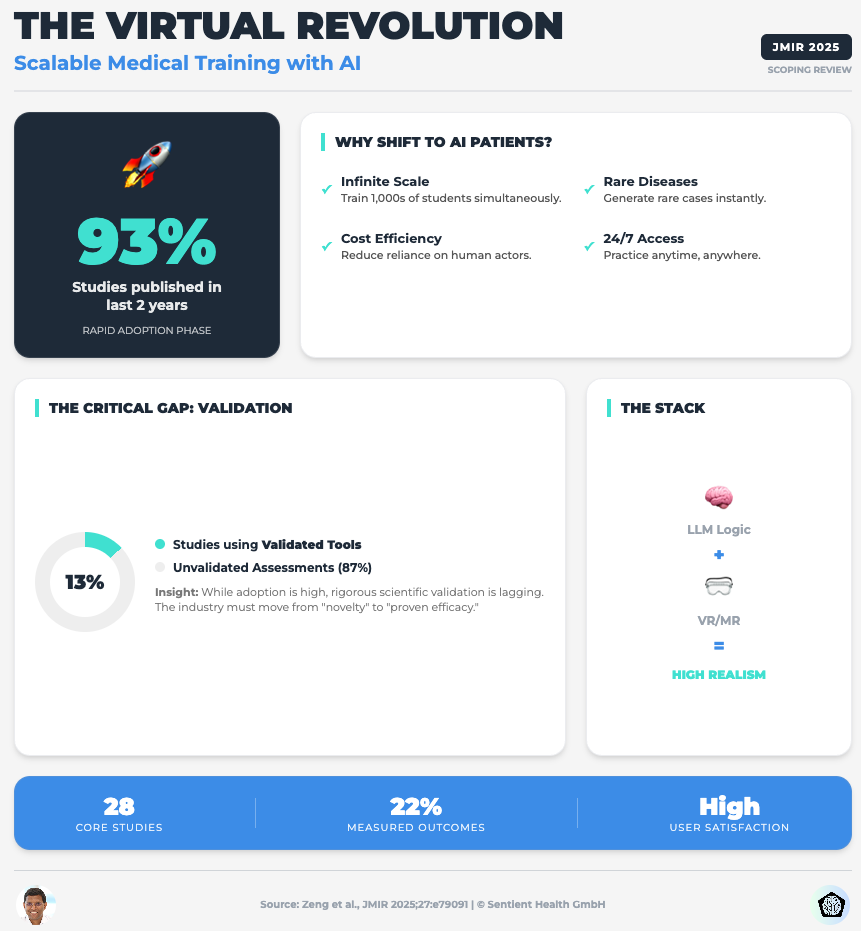
Embracing the Future of Medical Education With LLM-Based Virtual Patients (Read time: 22 mins)
Summary: A scoping review on using LLMs for simulation and training. It identifies a critical flaw: 87% of studies lack validated evaluation tools, and most rely on proprietary models (like GPT) that can change without notice, killing scientific reproducibility.
Key Takeaway: Move away from closed-source “black box” APIs for critical tools. To ensure data privacy and long-term reproducibility, you must prioritize open-source or local LLMs where you control the training data and parameters.
3 Steps To Tame AI Chaos With Strategic Governance Even If You Lack Technical Expertise
In order to achieve faster trials without exposing your organization to massive risk, you’re going to need a framework, not just a tech stack.
We often think “innovation” means buying the newest software. But in the current climate, innovation means having the discipline to validate what you build.
1. Optimize Eligibility Before You Recruit
The first thing you need to do is stop using AI just for data analysis and start using it for protocol design.
Why:
Traditional inclusion/exclusion criteria are often arbitrary and overly restrictive, leading to the enrollment crises we see today. The research shows that applying Machine Learning to Real-World Data (like EHRs) can identify where your criteria are too tight without impacting safety.
What to do:
Direct your data science teams to run simulations on your proposed eligibility criteria against RWD sets. Look for the “hidden” patients who are excluded by non-safety-critical factors. This can double your eligible pool before you open a single site.
2. Operationalize “VVUQ” Immediately
You need to integrate Verification, Validation, and Uncertainty Quantification (VVUQ) into your project management lifecycle.
Why:
“Black box” AI is a liability. If you cannot explain how a model reached a conclusion (Explainable AI or XAI), you cannot use it for clinical decision support. As the new data on virtual patients shows, reliance on unvalidated, proprietary models creates a reproducibility crisis.
What to do:
Don’t let a pilot project move to the next phase unless it has a “VVUQ Scorecard.” Ask your teams: Have we quantified the uncertainty? Is the model robust against edge cases? If OpenAI updates their model tomorrow, does our tool break? If the answer creates risk, the model stays in the lab.
3. Be Your Own Regulator
You need to mandate the use of CONSORT-AI and SPIRIT-AI reporting guidelines for every internal report and draft manuscript.
Why:
As the data showed, scientific journals are lagging behind. They aren’t catching hallucinations or methodological flaws in AI papers. If you rely on the peer-review process to validate your AI methods, you are exposing your firm to retraction risks later.
What to do:
Create a checklist based on these reporting guidelines. Make it a requirement for internal sign-off. By holding your internal teams to a higher standard than the journals do, you ensure that your data is bulletproof when it reaches the FDA or EMA.
PS...If you're enjoying Healthtech for Lifescience Leaders, please consider referring this edition to a friend.
And whenever you are ready, there are 2 ways I can help you:
AI Roadmap Kickstart Guide: Download my free guide on the 7 critical questions every pharma leader must answer before launching an AI initiative.
Strategy Session: Book a complimentary 30-minute AI Strategy Session with me to diagnose the biggest opportunities for AI within your current R&D pipeline.